Origins of 10X – How Valid is the Underlying Research?

Steve McConnell
Construx CEO / Author Code Complete
I had the chance to contribute a chapter to Making Software (Oram and Wilson, eds., O’Reilly). The purpose of this edited collection of essays is to pull together research-based writing on software engineering. In essence, the purpose is to say, “What do we really know (quantitatively based), and what do we only kind of think we know (subjectively based)?” My chapter, “What Does 10X Mean” is an edited version of my blog entry “Productivity Variations Among Developers and Teams: The Origin of 10x.” The chapter focuses on the research that supports the claim of 10-fold differences in productivity among programmers.
Laurent Bossavit published a critique of my blog entry on his company’s website in French. That critique was translated into English on a different website.
The critique (or its English translation, anyway) is quite critical of the claim that programmer productivity varies by 10x, quite critical of the research foundation for that claim, and quite critical of me personally. The specific nature of the criticism gives me an opportunity to talk about the state of research in software development, my approach to writing about software development, and to revisit the 10x issue, which is one of my favorite topics.
The State of Software Engineering Research
Bossavit’s criticism of my writing is notable for the fact that it cites my work, comments on some of the citations that my work cites, but doesn’t cite any other software-specific research of its own.
In marked contrast, while I was working on the early stages of Code Complete, 1st Ed., I read a paper by B. A. Sheil titled “The Psychological Study of Programming” (Computing Surveys, Vol. 13. No. 1, March 1981). Sheil reviewed dozens of papers on programming issues with a specific eye toward the research methodologies used. The conclusion of Sheil’s paper was sobering. The programming studies he reviewed failed to control for variables carefully enough to meet research standards that would be needed for publication in other more established fields like psychology. The papers didn’t achieve levels of statistical significance good enough for publication in other fields either. In other words, the research foundation for software engineering (circa 1981) was poor.
One of the biggest issues identified was that studies didn’t control for differences in individual capabilities. Suppose you have a new methodology you believe increases productivity and quality by 50%. If there are potential differences as large as 10x between individuals, the differences arising from individuals in any given study will drown out any differences you might want to attribute to a change in methodology. See Figure 1.
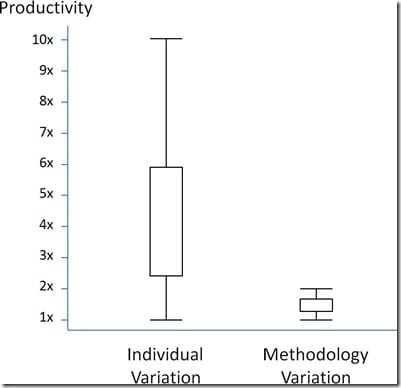
Figure 1
This is a very big deal because almost none of the research at the time I was working on Code Complete 1 controlled for this variable. For example, a study would have Programmer Group A read a sample of code formatted using Technique X and Programmer Group B read a sample of code formatted using Technique Y. If Group A was found to be 25% more productive than Group B, you don’t really know whether it’s because Technique X is better than Technique Y and is helping productivity, or whether it’s because Group A started out being way more productive than Group B and Technique X actually hurt Group A’s productivity.
Since Sheil’s paper in 1981, this methodological limitation has continued to show up in productivity claims about new software development practices. For example, in the early 2000s the “poster child” project for Extreme Programming was the Chrysler C3 project. Numerous claims were made for XP’s effectiveness based on the productivity of that project. I personally never accepted the claims for the effectiveness of the XP methodology based on the C3 project because that project included rock star programmers Kent Beck, Martin Fowler, and Ron Jeffries, all working on the same project. The productivity of any project those guys work on would be at the top end of the bar shown on the left of Figure 1. Those guys could do a project using batch mode processing and punch cards and still be more productive than 95% of the teams out there. Any methodological variations of 1x or 2x due to XP (or -1x or -2x) would be drowned out by the variation arising from C3’s exceptional personnel. In other words, considering the exceptional talent on the C3 project, it was impossible to tell whether the C3 project’s results were because of XP’s practices or in spite of XP’s practices.
My Decision About How to Write Code Complete
Bringing this all back to Code Complete 1, I hit a point early in the writing of Code Complete 1 where I was aware of Sheil’s research, aware of the limitations of many of the studies I was using, and trying to decide what kind of book I wanted to write.
The first argument I had with myself was how much weight to put on all the studies I had read. I read about 600 books and articles as background for Code Complete. Was I going to discard them altogether? I decided, No. The studies might not be conclusive, but many of them were surely suggestive. The book was being written by me and ultimately reflected my judgment, so whether the studies were conclusive or suggestive, my role as author was the same–separate the wheat from the chaff and present my personal conclusions. (There was quite a lot of chaff. Of the 600 books and articles I read, only about half made it into the bibliography. Code Complete’s bibliography includes only those 300 books and articles that were cited somewhere in the book.)
The second argument I had with myself was how much detail to provide about the studies I cited. The academic side of me argued that every time I cited a study I should explain the limitations of the study. The pragmatic side of me argued that Code Complete wasn’t supposed to be an academic book; it was supposed to be a practical book. If I went into detail about every study I cited, the book would be 3x as long without adding any practical value for its readers.
In the end I felt that detailed citations and elaborate explanations of each study would detract from the main focus of the book. So I settled on a citation style in which I cited (Author, Year) keyed to fuller bibliographic citations in the bibliography. I figured readers who wanted more academic detail could follow up on the citations themselves.
A Deeper Dive Into the Research Supporting “10x”
After settling on that approach with Code Complete 1 (back in 1991) I’ve continued to use that approach in most of the rest of my writing, including in the chapter I contributed to Making Software.
One limitation of my approach has been that, with my terse citation style, someone who is motivated enough to follow up on the citations might not be able to find the part of the book or article that I was citing, or might not understand the specific way in which the material I cited supports the point I’m making. That appears to have been the case with Laurent Bossavit’s critique of my “10x” explanation.
Bossavit goes point by point through my citations and was not able to find the support for the claim of 10x differences in productivity. Let’s follow the same path and fill in the blanks.
Sackman, Erickson, and Grant, 1968. Here is my summary of the first research to find 10x differences in programmer productivity:
Detailed examination of Sackman, Erickson, and Grant’s findings shows some flaws in their methodology (including combining results from programmers working in low level programming languages with those working in high level programming languages). However, even after accounting for the flaws, their data still shows more than a 10-fold difference between the best programmers and the worst.
In years since the original study, the general finding that “There are order-of-magnitude differences among programmers” has been confirmed by many other studies of professional programmers (Curtis 1981, Mills 1983, DeMarco and Lister 1985, Curtis et al. 1986, Card 1987, Boehm and Papaccio 1988, Valett and McGarry 1989, Boehm et al 2000).
The research on variations among individual programmers began with Sackman, Erickson, and Grant’s study published in 1968. Bossavit states that the 1968 study focused only on debugging, but that is not correct. As I stated in my blog article, the ratio of initial coding time between the best and worst programmers was about 20:1. The difference in program sizes was about 5:1. The difference in debugging was the most dramatic difference, at about 25:1, but it was not the only area in which differences were found. Differences found in coding time, debugging time, and program size all support a general claim of “order of magnitude” differences in productivity, i.e., a 10x difference.
An interesting historical footnote is that Sackman, Erickson, and Grant did not set out to show a 10x or 25x difference in productivity among programmers. The purpose of their research was to determine whether programming online offered any real productivity advantage compared to programming offline. What they discovered, to their surprise, was that, ala Figure 1, any difference in online vs. offline productivity was drowned out by the productivity differences among individuals. The factor they set out to study would be irrelevant today. The conclusion they stumbled onto by accident is one that we’re still talking about.
Curtis 1981. Bossavit criticizes my (Curtis 1981) citation by stating
The 1981 Curtis study included 60 programmers, which once again were dealing with a debugging rather than a programming task.
I do not know why he thinks this statement is a criticism of the Curtis study. In my corner of the world debugging is not the only programming task, but it certainly is an essential programming task, and everyone knows that. The Curtis article concludes that, “a statement such as ‘order of magnitude differences in the performance of individual programmers’ seems justified.” The (Curtis 1981) citation directly supports the 10x claim–almost word for word.
Curtis 1986. Moving to the next citation, Bossavit states that, “the 1986 Curtis article does not report on an empirical study.” I never stated that Curtis 1986 was an “empirical study.” Curtis 1986 is a broad paper that touches on, among other things, differences in programmer productivity. Bossavit says the paper “offers no support for the ’10x’ claim.” But the first paragraph in section II.A. of the paper (p. 1093) summarizes 4 studies with the overall gist of the studies being that there are very large differences in productivity among programmers. The specific numbers cited are 28:1 and 23:1 differences. Clearly that again offers direct support for the 10x claim.
Mills 1983. The “Mills 1983” citation is to a book by Harlan Mills titled Software Productivity in which Mills cites 10:1 differences in productivity not just among individuals but also among teams. As Bossavit points out, the Mills book contains “experience reports,” among other things. Apparently Bossavit doesn’t consider an “experience report” to be a “study,” but I do, which is why I cited Mills’ 1983 book.
DeMarco and Lister 1985. Bossavit misreads my citation of DeMarco and Lister 1985, assuming it refers to their classic book Peopleware. That is a natural assumption, but as I stated clearly in the article’s bibliography, the reference was to their paper titled, “Programmer Performance and the Effects of the Workplace” which was published a couple years before PeopleWare.
Bossavit’s objection to this study is
The only “studies” reported on therein are the programming contests organized by the authors, which took place under loosely controlled conditions (participants were to tackle the exercises at their workplace and concurrently with their work as professional programmers), making the results hardly dependable.
Editorial insinuations aside, that is a correct description of what DeMarco and Lister reported, both in the paper I cited and in Peopleware. Their 1985 study had some of the methodological limitations Sheil’s discussed in 1981. Having said that, their study supports the 10x claim in spades and is not subject to many of the more common methodological weaknesses present in other software engineering studies. DeMarco and Lister reported results from 166 programmers, which is a much larger group than used in most studies. The programmers were working professionals rather than students, which is not always the case. The focus of the study was a complete programming assignment–design, code, desk check, and for part of the group, test and debug.
The programmers in DeMarco and Lister’s study were trying to complete an assignment in their normal workplace. Bossavit seems to think that undermines the credibility of their research. I think it enhances the credibility of their research. Which do you trust more: results from a study in which programmers worked in a carefully controlled university environment, or results from a study in which programmers were subjected to all the day-to-day interruptions and distractions that programmers are subjected to in real life? Personally I put more weight on the study that more closely models real-world conditions, which is why I cited it.
As far as the 10x claim goes, Bossavit should have looked at the paper I cited rather than the book. The paper shows a 5.6x difference between the best and worst programmers–among the programmers who finished the assignment. About 10% of the programmers weren’t able to complete the assignment at all. That makes the difference between best and worst programmers essentially infinite – and certainly supports the round-number claim of 10x differences from the best programmers to the worst.
Card 1987. Bossavit says,
The 1987 Card reference isn’t an academic publication but an executive report by a private research institution, wherein a few tables of figures appear, none of which seem to directly bear on the “10x” claim.
The publication is an article in Information and Software Technology, which is “the international archival journal focusing on research and experience that contributes to the improvement of software development practices.” There is no basis for Bossavit to characterize Card’s journal article as an “executive report.”
Bossavit claims that none of the tables of figures “seem to directly bear on the ’10x’ claim.” But on p. 293 of the article, Figure 3, titled “Programmer productivity variations,” shows two graphs: a “large project” graph in which productivity ranges from 0.9 to 7.9 (a difference of 8.8x ), and a “small project” graph with a productivity range of 0.5 to 10.8 (a difference of 21.6x). These “programmer productivity variation” graphs support the 10x claim quite directly.
Boehm and Papaccio 1988. I will acknowledge that this wasn’t the clearest citation for the underlying research I meant to refer to. I probably should have cited Boehm 1981 instead. In 1981, Barry Boehm published Software Engineering Economics, the first comprehensive description of the Cocomo estimation model. The adjustment factors for the model were derived through analysis of historical data. The model shows differences in team productivity based on programmer capability of 4.18 to 1. This is not quite an order of magnitude, but it is for teams, rather than for individuals, and generally supports the claim that “there are very large differences in capabilities between different individuals and teams.”
Boehm 2000. Bossavit states that he did not look at this source. Boehm 2000 is Software Cost Estimation with Cocomo II, the update of the Cocomo model that was originally described in Boehm 1981. In the 2000 update, the factors in the Cocomo model were calibrated using data from a database of about 100 projects. Cocomo II analyzes the effects of a number of personnel factors. According to Cocomo II, if you compare a team made up of top-tier programmers, experienced with the application, programming language, and platform they’re using, to a team made up of bottom tier programmers, inexperienced with the application, programming language, and platform they’re using, you can expect a difference of 5.3x in productivity.
The same conclusion applies here that applies to Boehm 1981: This is not quite an order of magnitude difference, but since it applies to teams rather than individuals, it generally supports the claim that “there are very large differences in capabilities between different individuals and teams.” It is also significant that, according to Cocomo II, the factors related to the personnel composing the team affect productivity more than any other factors.
Valett and McGarry 1989. Valett and McGarry provide additional detail from the same data set used by Card 1987 and also cites individual differences ranging from 8.8x to 21.6x. Valett and McGarry’s conclusion is based on data from more than 150 individuals across 25 major projects and includes coding as well as debugging. Bossavit claims this study amounts to a “citation of a citation,” but I don’t know why he claims that. Valett and McGarry were both at the organization described in the study and directly involved in it. And the differences cited certainly support my general claim of 10x differences in productivity among programmers.
Reaffirming: Strong Research Support for the 10x Conclusion
To summarize, the claim that Bossavit doesn’t like, is this:
The general finding that “There are order-of-magnitude differences among programmers” has been confirmed by many other studies of professional programmers (Curtis 1981, Mills 1983, DeMarco and Lister 1985, Curtis et al. 1986, Card 1987, Boehm and Papaccio 1988, Valett and McGarry 1989, Boehm et al 2000).
As I reviewed these citations once again in writing this article, I concluded again that they support the general finding that there are 10x productivity differences among programmers. The studies have collectively involved hundreds of professional programmers across a spectrum of programming activities. Specific differences range from about 5:1 to about 25:1, and in my judgment that collectively supports the 10x claim. Moreover, the research finding is consistent with my experience, in which I have personally observed 10x differences (or more) between different programmers. I think one reason the 10x claim resonates with many people is that many other software professionals have observed 10x differences among programmers too.
Bossavit concludes his review of my blog entry/book chapter by saying this:
What is happening here is not pretty. I’m not accusing McConnell here of being a bad person. I am claiming that for whatever reasons he is here dressing up, in the trappings of scientific discourse, what is in fact an unsupported assertion meshing well with his favored opinion. McConnell is abusing the mechanism of scientific citation to lend authority to a claim which derives it only from a couple studies which can be at best described as “exploratory” (and at worst, maybe, as “discredited”).
Obviously I disagree with Bossavit’s conclusion. Saying he thinks there are methodological weaknesses in the studies I cited would be one kind of criticism that might contain a grain of truth. None of the studies are perfect, and we could have a constructive dialog about that. But that isn’t what he says. He says I am making “unsupported assertions” and “cheating with citations.” Those claims are unfounded. Bossavit seems to be aspiring to some academic ideal in which the only studies that can be cited are those that are methodologically pure in every respect. That’s a laudable ideal, but it would have the practical effect of restricting the universe of allowable software engineering studies to zero.
Having said that, the body of research that supports the 10x claim is as solid as any research that’s been done in software engineering. Studies that support the 10x claim are singularly not subject to the methodological limitation described in Figure 1, because they are studying individual variability itself (i.e., only the left side of the figure). Bossavit does not cite even one study–flawed or otherwise–that counters the 10x claim, and I haven’t seen any such studies either. The fact that no studies have produced findings that contradict the 10x claim provides even more confidence in the 10x claim. When I consider the number of studies that have been conducted, in aggregate I find the research to be not only suggestive, but conclusive–which is rare in software engineering research.
As for my writing style, even if people misunderstand what I’ve written from time to time, I plan to stand by my practical-focus-with-minimal-citations approach. I think most readers prefer the one paragraph summary with citations that I repeated at the top of this section to the two dozen paragraphs that academically dissect it. It’s interesting to go into that level of detail once in awhile, but not very often.
References
Boehm, Barry W., and Philip N. Papaccio. 1988. “Understanding and Controlling Software Costs.” IEEE Transactions on Software Engineering SE-14, no. 10 (October): 1462-77.
Boehm, Barry, 1981. Software Engineering Economics, Boston, Mass.: Addison Wesley, 1981.
Boehm, Barry, et al, 2000. Software Cost Estimation with Cocomo II, Boston, Mass.: Addison Wesley, 2000.
Boehm, Barry W., T. E. Gray, and T. Seewaldt. 1984. “Prototyping Versus Specifying: A Multiproject Experiment.” IEEE Transactions on Software Engineering SE-10, no. 3 (May): 290-303. Also in Jones 1986b.
Card, David N. 1987. “A Software Technology Evaluation Program.” Information and Software Technology 29, no. 6 (July/August): 291-300.
Curtis, Bill. 1981. “Substantiating Programmer Variability.” Proceedings of the IEEE 69, no. 7: 846.
Curtis, Bill, et al. 1986. “Software Psychology: The Need for an Interdisciplinary Program.” Proceedings of the IEEE 74, no. 8: 1092-1106.
DeMarco, Tom, and Timothy Lister. 1985. “Programmer Performance and the Effects of the Workplace.” Proceedings of the 8th International Conference on Software Engineering. Washington, D.C.: IEEE Computer Society Press, 268-72.
DeMarco, Tom and Timothy Lister, 1999. Peopleware: Productive Projects and Teams, 2d Ed. New York: Dorset House, 1999.
Mills, Harlan D. 1983. Software Productivity. Boston, Mass.: Little, Brown.
Sackman, H., W.J. Erikson, and E. E. Grant. 1968. “Exploratory Experimental Studies Comparing Online and Offline Programming Performance.” Communications of the ACM 11, no. 1 (January): 3-11.
Sheil, B. A. 1981. “The Psychological Study of Programming,” Computing Surveys, Vol. 13. No. 1, March 1981.
Valett, J., and F. E. McGarry. 1989. “A Summary of Software Measurement Experiences in the Software Engineering Laboratory.” Journal of Systems and Software 9, no. 2 (February): 137-48.




